数据库执行引擎的内存仲裁模式:从 OOM 保护到资源管控
数据库执行引擎的内存管理,真正难点不在于统计单条 SQL 用了多少内存,而在于当多个 SQL、后台任务和运行时系统共同竞争实例内存时,如何在 OOM 之前做出可解释的全局决策。传统“先分配、后统计、超限再杀 SQL”的方式处理得太晚,难以表达业务优先级,也无法覆盖逻辑内存与真实进程内存之间的偏差。本文围绕 TiDB 执行引擎的内存仲裁模式,讨论稳定性、利用率、公平性和优先级保护之间的设计取舍。
本文要解决的问题
数据库执行引擎中,内存管理面临的难题是:
- 当多个 SQL 同时增长内存时,系统应该让谁继续执行?
- 当实例内存已经紧张时,新来的内存申请是等待、失败,还是抢占其他 SQL?
- 当进程接近 OOM 时,应该取消哪个 SQL,还是强制终止正在运行的 SQL?
- 如何让 OLTP、OLAP、后台任务在同一个 TiDB 实例上有不同的资源保障?
传统方式有什么问题
传统做法大致是:
1 | SQL 执行 |
这种方式有优点:简单、侵入小、容易落地。但它有一个根本问题:处理得太晚。
等实例内存已经超过阈值时,通常已经发生了下面这些事情:
- Go 堆内存已经很高,GC 压力已经出现。
- SQL 已经分配了大量对象,强制终止后也不一定马上释放。
- 系统只能看到“谁用得多”,但不知道“谁应该被保护”。
- 所有 SQL 在全局内存风险面前几乎是同一类,业务优先级很难体现。
所以,仅靠事后强制终止内存使用最多的 SQL,不能解决执行引擎的资源竞争问题。我们需要在 SQL 继续扩大内存占用之前,就进行全局判断。
设计目标
目标
- 保障 TiDB 实例内存安全,避免 OOM。
- 减少极端内存压力下的 GC 抖动。
- 让 SQL 因内存不足而失败时,原因更明确、更可解释。
- 支持按业务优先级调度内存资源。
- 在内存充足时保持低开销,不影响普通小查询。
- 为后续更统一的执行引擎资源管控打基础。
核心思路:先申请额度,再继续用内存
内存仲裁的核心变化是:
1 | Before: |
这里的“额度”可以理解为逻辑内存预算。SQL 不一定真的马上分配这么多物理内存,但它需要先向系统声明:我接下来可能需要更多内存。
全局仲裁器收到申请后,会根据当前实例状态做决定:
- 内存充足:允许申请。
- 内存紧张:让申请等待,或者取消申请。
- 有优先级差异:保护高优先级 SQL,回收低优先级 SQL。
- 已经接近 OOM 风险:强制终止部分正在运行的 SQL,优先保护 TiDB 进程。
这个设计的关键不是“限制每个 SQL”,而是“在实例级别做资源决策”。
为什么不能只靠单 SQL 内存上限
单 SQL 内存上限只能回答“这个 SQL 有没有超过自己的限制”,不能回答“整个 TiDB 实例是否还安全”。
极端情况下,每个 SQL 都没有超过自己的内存上限,但并发叠加后,实例堆内存仍然可能进入危险区。反过来,有些 SQL 的逻辑额度不高,但由于未追踪对象、临时对象或 GC 滞后,也可能造成真实内存压力。
这就是为什么需要实例级仲裁器,而不是只依赖 SQL 自己的内存上限。
总体架构
内存仲裁可以分成三层。
1 | SQL / 执行器 / 计划器 / 编译器 |
下图表示 TiDB 内存仲裁模式的总体架构
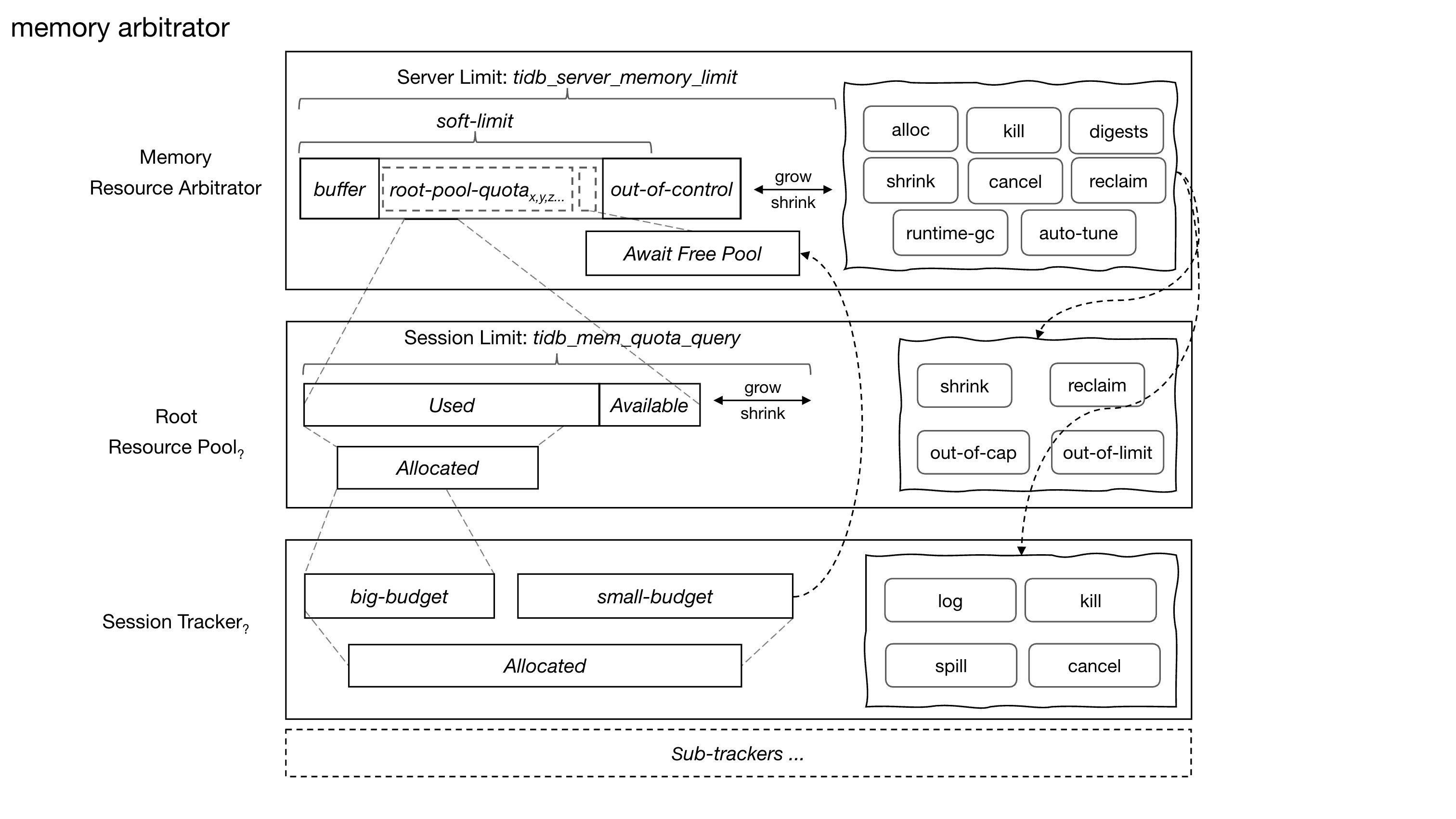
内存追踪器(Memory Tracker):追踪统计入口
执行器、算子、编译器、优化器仍然通过内存追踪器记录内存变化。
这样做的好处是:
- 不需要让所有算子直接感知全局仲裁器。
- 保留已有的 SQL 内存统计和诊断能力。
- 让内存仲裁可以逐步接入,而不是重写执行器内存管理。
内存资源池(Memory Resource Pool):给 SQL 建资源账户
内存资源池可以理解为 SQL 或任务的内存账户。
它记录这个任务已经获得了多少额度、用了多少额度、还能不能继续扩容。当 SQL 的内存使用变大时,它不是直接无限增长,而是通过自己的内存账户向上申请更多额度。
这一层解决的是“内存归谁”的问题。它内部可以分成两类路径:
- root pool(执行内存账户):用于执行阶段持续增长、可能需要等待或回收的内存。
- await-free pool(快速额度池):用于短生命周期内存和小额度增长。
await-free pool:短生命周期内存的快速路径
不是所有内存使用都适合进入完整的 root pool 仲裁流程。
解析、编译这类阶段生命周期短,内存使用更多依赖估算。如果它们每次都进入普通等待队列,仲裁器会承受不必要的调度开销。因此当前 TiDB 会按 SQL 复杂度估算一段临时额度,通过 await-free pool 占用,阶段结束后释放。
执行阶段也会先使用 await-free pool 的小额度路径。当 SQL 内存增长超过小额度阈值,或者 await-free pool 无法继续补充额度时,SQL 才升级到 root pool,进入完整的等待、回收和优先级仲裁流程。
await-free pool 不是绕过仲裁。它仍然受全局额度约束,只是不进入执行阶段的 root pool 普通等待队列。这个设计把短生命周期内存和小额度增长纳入全局视野,同时避免热路径被过度调度。
全局内存仲裁器(Global Memory Arbitrator):做实例级决策
全局内存仲裁器是实例级决策者。每个 TiDB 实例有一个仲裁器。
它负责回答:
- 当前实例还剩多少可分配内存额度?
- 哪些 SQL 正在等待额度?
- 哪些 SQL 是高优先级,哪些是低优先级?
- 当前运行时内存是否已经危险?
- 如果资源不够,应该取消、等待、回收还是强制终止?
这一层解决的是“系统还能不能继续分配”的问题。
核心设计难点:逻辑额度和真实内存不一致
内存仲裁最难的地方,不是维护一个全局计数器,而是判断“还有多少内存可以安全分配”。
SQL 内存追踪器记录的是逻辑内存使用,Go 运行时暴露的是进程真实内存状态。两者经常不一致:
- SQL 内存追踪器不一定覆盖所有临时对象。
- SQL 释放对象后,Go 堆内存不一定马上下降。
- 运行时、goroutine 栈、堆外内存、缓存、后台任务都会占用内存。
- 有些内存很难准确归属到某个 SQL。
- 同样的逻辑额度,在不同负载下可能对应不同的堆内存压力。
因此,全局仲裁器不能简单地用下面这个公式做决策:
1 | 可分配额度 = 实例内存上限 - 已分配额度 |
这个公式看起来合理,但会漏掉一大块风险:已经在进程里、但不在 SQL 逻辑额度里的内存。它们可能来自 GC 滞后,也可能来自未追踪对象,还可能来自系统后台任务。
这意味着系统需要为“无法安全继续分配的风险空间”建模。这个风险空间在后文称为 out-of-control(失控风险空间)。
一条 SQL 的执行流程
简化后的流程如下:
1 | SQL 开始执行 |
这里有一个重要取舍:不是每一次内存增长都进入全局仲裁。
如果所有小对象分配都进入全局队列,仲裁器本身会成为性能瓶颈。所以当前设计保留了轻量路径:
- 解析、编译这类短生命周期阶段通过 await-free pool 使用估算额度。
- 执行阶段的小额度增长也先走 await-free pool。
- 只有当增长超过小额度阈值,或者 await-free pool 不能继续补充额度时,才进入执行阶段的 root pool 仲裁。
这个取舍牺牲了一点控制精度,换来正常路径的低开销。
两种工作模式
内存不足时,不同业务希望的行为不一样。有些系统希望尽快失败并重试;有些系统希望保护关键 SQL。因此仲裁器提供不同模式。
STANDARD 模式:简单公平的默认仲裁
STANDARD 模式强调简单、公平、可解释。SQL 运行过程中动态申请内存额度;资源不足时,申请会按顺序等待。如果全局内存仍然不足,仲裁器才会让申请失败并取消对应 SQL。
这个模式不表达业务优先级。它适合先建立一套全局内存准入和等待机制,再由上层重试或其他策略处理失败。
适合场景:
- 希望行为简单、可预测。
- 不需要区分业务优先级。
- 可以接受 SQL 在资源不足时等待,或者最终失败后由上层重试。
取舍:
- 好处:规则简单,同一类 SQL 之间更公平。
- 代价:不能保护关键业务;资源紧张时可能增加等待时间。
PRIORITY 模式:保护高优先级 SQL
PRIORITY 模式下,SQL 会带有内存优先级。优先级可以来自 Resource Group(资源组)。
这里需要注意:资源组可以有多个,但当前内存仲裁消费的是资源组上的三档优先级:LOW、MEDIUM、HIGH。也就是说,它表达的是资源紧张时的保护顺序,不是完整的内存配额、保底或隔离模型。
当内存不足时,系统会优先保护高优先级 SQL,并尝试取消或回收低优先级 SQL。
适合场景:
- OLTP 和 OLAP 混合部署。
- 关键业务需要更高保障。
- 可以接受低优先级查询在资源紧张时更容易失败。
取舍:
- 好处:可以表达业务重要性。
- 代价:优先级粒度较粗,低优先级 SQL 可能被频繁取消;如果大量资源组都配置成 HIGH,模式会退化。
除了 STANDARD 和 PRIORITY,系统还可以支持更细的等待策略。例如低延迟请求可以选择不在当前 TiDB 节点等待内存释放,而是快速取消,交给上层重试。这类策略不是新的仲裁模型,而是对“资源不足时是否等待”的补充。
配置入口:表达策略,不替代架构
从用户接口看,内存仲裁需要把几个关键策略暴露出来:是否启用仲裁、采用哪种仲裁模式、soft limit 如何设置、单个 SQL 是否显式预留内存资源、资源不足时是否倾向快速失败。
这些配置不应该被理解成新的架构层。它们只是把前面的设计选择变成可操作的入口:
- 仲裁模式决定资源不足时按公平顺序处理,还是按业务优先级处理。
- soft limit 决定全局内存额度边界,是安全性和利用率之间的调节旋钮。
- query reserved 用于提高单个 SQL 的隔离性,减少执行过程中多次申请额度的开销。
- 快速失败策略用于低延迟业务,让 SQL 不在当前 TiDB 节点长时间等待,而是交给上层重试。
这部分在架构上最重要的不是变量名字,而是用户能把业务意图表达给执行引擎。
CANCEL 和 KILL 的区别
内存仲裁必须区分两件事:
- 只是没有足够额度。
- TiDB 进程已经接近 OOM。
这里的 KILL 指强制终止 SQL 执行,不是终止 TiDB 进程。
对应的处理也不同:
1 | 额度不足 -> CANCEL |
CANCEL
CANCEL 是普通资源不足时的处理方式。它说明 SQL 没有拿到足够额度,或者系统希望它让出资源。
CANCEL 是调度行为,不一定表示实例已经危险。
KILL
KILL 是最后保护手段。只有当运行时内存已经进入危险区,并且 GC 或自然释放无法及时降低压力时,才应该强制终止正在运行的 SQL。
这个区分很重要。否则所有内存不足都会变成强制终止,用户体验会很差,也很难解释。
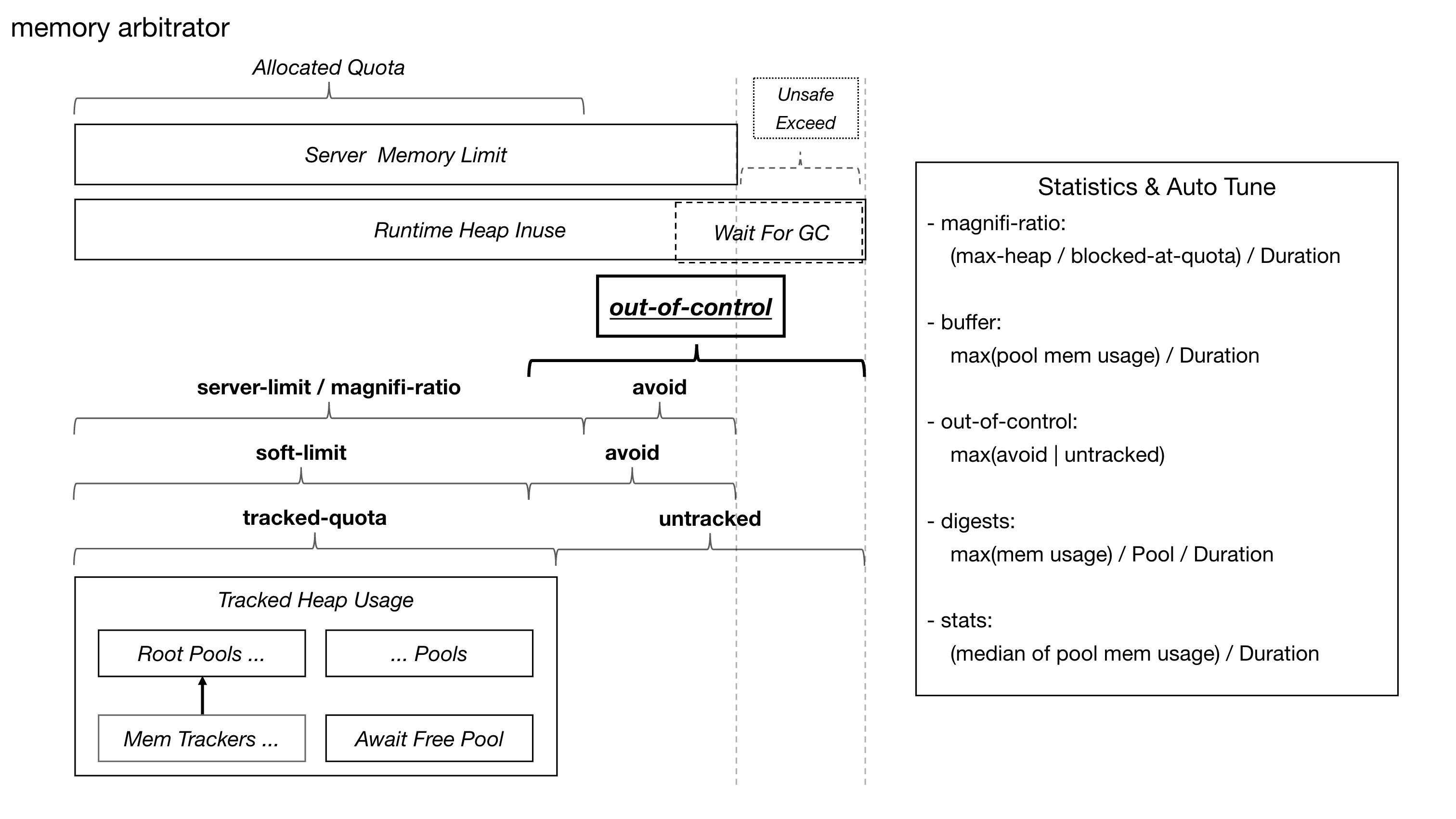
out-of-control:风险空间的建模
out-of-control 指的是仲裁器不应该继续分配出去的那部分内存空间。它不一定都是“未追踪内存”,也包括因为 soft limit(软上限)、GC 滞后、运行时开销等原因需要保留的安全空间。
全局仲裁不能只看 SQL 内存追踪器统计出来的内存。真实进程内存还包括:
- Go 堆内存中等待 GC 的对象。
- 未被内存追踪器精确统计的临时对象。
- goroutine 栈。
- 运行时和堆外内存开销。
- 缓存和后台任务。
系统需要在硬限制下面留出安全空间,这个安全空间就是 out-of-control 估算的主要结果。
换成仲裁器的分配模型,就是:
1 | 可安全分配额度 ~= 实例内存上限 - 已分配额度 - buffer - out-of-control |
可以把实例内存理解成:
1 | 实例内存上限 |
可以把 out-of-control 理解成几类风险的最大值:
1 | out-of-control = |
soft limit 是其中一个重要来源。它用来控制“最多分配多少额度给 SQL”,确保系统不会把硬限制全部暴露给执行层。
下图展示了 TiDB 内存仲裁模式中 out-of-control、soft limit、未追踪内存和历史画像之间的关系。
buffer 和死锁规避
动态内存仲裁还有一个容易被忽略的问题:所有 root pool 都在等待额度时,系统不能让仲裁过程本身也被阻塞。否则会出现“大家都在等别人释放内存,但没有人能够继续推进到释放点”的风险。
因此,仲裁器需要保留一部分 buffer,用来支持取消、回收、状态推进等必要动作。在优先级模式下,还可以引入类似 privileged budget(特权额度)的机制:极端情况下,只允许一个 root pool 继续向前推进,直到它释放资源或完成退出。
这个设计的收益是避免全局卡死;代价是极端压力下并发度可能下降,甚至退化成接近单并发推进。它不是为了提高性能,而是为了在资源已经紧张时保证系统仍然能完成回收动作。
取舍:
- out-of-control 估算越高,系统越安全,但 SQL 更容易等待或取消。
- out-of-control 估算越低,内存利用率越高,但更容易触发 GC 抖动或 OOM。
- soft limit 可以采用自动计算方式,但它只是风险边界的调节方式,不是独立的仲裁模式。
估算没有完美答案:
| 估算偏高 | 估算偏低 |
|---|---|
| 更安全 | 内存利用率更高 |
| SQL 更早等待或取消 | SQL 更容易继续执行 |
| 可能浪费可用内存 | 更容易触发 GC 抖动或 OOM |
| 用户感知是“太保守” | 用户感知是“不稳定” |
因此,仲裁器的目标不是算出一个绝对准确的 out-of-control,而是在安全性和利用率之间找到一个能动态调整的边界。
runtime feedback:逻辑额度之外的真实世界
逻辑额度和真实内存不是一回事。
一个 SQL 可能只报告了一部分内存,但 Go 运行时里还有未释放对象;也可能 SQL 已经退出,但堆内存还没被 GC 回收。因此,仲裁器不能只看 SQL 的逻辑额度,还要看运行时内存。
runtime feedback 主要用于回答:
- 当前堆内存是否已经很高?
- 是否有大量未追踪内存?
- GC 是否能及时释放内存?
- 逻辑额度和真实堆内存之间是否长期不匹配?
也就是说,out-of-control 给出风险边界,runtime feedback 负责根据运行状态修正这个边界。
它的作用是把仲裁器从固定阈值判断变成闭环控制:
- 先根据逻辑额度做分配。
- 再观察真实堆内存是否按预期变化。
- 如果堆内存压力明显高于额度预期,就扩大 out-of-control。
- 如果风险解除,再逐步释放保守余量。
这类控制一定不是完全精确的,但比固定阈值更能适应不同负载。
引入 runtime feedback 的取舍是:
- 好处:更接近真实进程状态,能减少 OOM。
- 代价:系统行为会受运行时波动影响,解释成本更高。
Auto Tune:把反馈变成下一轮决策
Auto Tune 是内存仲裁的自适应校正机制,用 runtime feedback 和历史画像修正额度决策。
短期看,它根据运行时内存压力调整 out-of-control,让系统在风险升高时更保守,在风险解除后逐步释放保守余量。长期看,它可以记录 SQL 或 root pool 的历史内存画像,用于改善下一次执行的额度预估,减少反复扩容和仲裁。
这不是新的仲裁模式,而是让仲裁器从静态阈值走向自适应决策的能力。写这部分时需要区分当前实现和演进方向:运行时状态记录、历史画像和 soft limit 自动模式提供了框架,但不能把它描述成已经能完美预测所有 SQL 内存使用。
和 Resource Group 的关系
内存仲裁可以复用 Resource Group 的业务语义。
当前更直接的用法,是复用 Resource Group 的业务优先级,让仲裁器在资源紧张时知道哪些 SQL 更应该被保护。
从更长期的架构看,Resource Group 不应该只表达 CPU 或 RU,也可以逐步表达更完整的执行策略:
1 | Resource Group |
这样用户配置的是业务意图,而不是每种资源的底层参数。
需要区分当前能力和演进方向:当前重点是把业务优先级接入内存仲裁;是否允许等待、是否倾向快速失败、是否允许落盘、后台任务如何隔离,更适合作为统一执行资源管控平面的扩展能力。
三档优先级是一个有意的简化。它的好处是配置简单、行为容易解释;风险是粒度偏粗。同一档里的 SQL 仍然可能互相竞争,LOW 在持续压力下可能长期等待或被取消,而 HIGH 如果被滥用,也会失去保护关键业务的意义。因此,Resource Group 接入内存仲裁后,应该被理解为“风险时的保护顺序”,而不是“按组隔离内存”的完整方案。
例如:
- OLTP:高优先级,低延迟,内存不足时可以快速失败并重试。
- OLAP:中低优先级,可以等待,可以落盘。
- 后台任务:低优先级,可以暂停或限速。
- 管理任务:高优先级,可以预留额度。
从这个角度看,内存仲裁不是孤立功能,而是 Resource Group 从“资源统计”走向“执行调度”的一部分。
推广到执行引擎资源管控
内存仲裁背后的模型可以推广到更多资源。
1 | 业务策略 |
不同资源可以套用类似模型:
- 内存:额度、资源池、GC、取消、强制终止、落盘。
- CPU:优先级、让出执行、限速。
- IO:队列、限速、准入。
- 网络:反压、流控。
- 临时磁盘:落盘额度、临时空间预算。
- 后台任务:暂停、恢复、低优先级调度。
内存是最适合作为起点的资源,因为它最容易导致进程不可用,也最难靠操作系统自然调度解决。
可观测性
内存仲裁必须可解释。否则用户只会看到 SQL 被取消或强制终止,却不知道为什么。
至少需要观察这些信息:
- 当前仲裁模式。
- 已分配额度、可用额度、风险空间。
- 等待额度的 SQL 数量。
- root pool 数量。
- 取消、强制终止、GC 次数。
- SQL 等待内存仲裁的耗时。
- 运行时堆内存和逻辑额度之间的比例。
- soft limit 与实例内存上限的关系。
这些信息可以帮助判断:
- 是整体内存不足,还是某类 SQL 消耗异常?
- 是 soft limit 太保守,还是负载本身太重?
- 是低优先级 SQL 被正常回收,还是关键 SQL 也受影响?
- 是应该调大资源、降低并发,还是调整 Resource Group?
主要取舍总结
稳定性 vs 利用率
系统会预留安全空间,不会把全部内存都分给 SQL。
- 收益:降低 OOM 和 GC 风险。
- 代价:极限内存利用率下降。
快速失败 vs 成功率
快速失败策略会让 SQL 更早失败。
- 收益:避免无界等待,降低尾延迟。
- 代价:更依赖上层重试。
优先级保护 vs 公平性
PRIORITY 模式保护高优先级业务。
- 收益:关键 SQL 更稳定。
- 代价:低优先级 SQL 可能更容易失败。
三档优先级 vs 细粒度隔离
当前 Resource Group 优先级只有 LOW、MEDIUM、HIGH 三档。
- 收益:配置简单,用户容易理解,仲裁器也容易做出稳定决策。
- 代价:同档内仍然会竞争;如果 HIGH 被滥用,优先级保护会退化;如果 LOW 长期承压,需要依赖等待策略、重试策略和可观测性来解释。
全局控制 vs 热路径开销
全局仲裁能做更强的控制,但不能参与每一次小内存分配。
- 收益:实例级资源调度能力更强。
- 代价:需要轻量路径来控制开销,因此精度不是绝对的。
await-free pool vs root pool
await-free pool 适合解析、编译和执行阶段的小额度增长,root pool 适合执行阶段持续增长、需要等待或回收的内存。
- 收益:短生命周期内存和小额度增长也能纳入全局额度视野,同时避免过早进入普通等待队列。
- 代价:需要判断什么时候从 await-free pool 升级到 root pool;升级太早会增加调度开销,升级太晚会增加 out-of-control 压力。
buffer vs 并发度
buffer 和 privileged budget 用于避免所有 root pool 同时等待导致系统无法回收。
- 收益:极端压力下仍能推进取消、回收和退出流程,降低全局卡死风险。
- 代价:会保留一部分不可分配空间;压力过大时并发度可能下降。
runtime feedback vs 可预测性
引入运行时内存可以更好地保护进程。
- 收益:能处理未追踪内存和 GC 滞后。
- 代价:决策会受到历史状态和运行时波动影响。
Auto Tune vs 可解释性
Auto Tune 用 runtime feedback 和历史画像修正额度决策。
- 收益:额度边界可以随负载变化自适应,减少固定阈值带来的误判。
- 代价:用户需要更多可观测性才能理解为什么同一类 SQL 在不同时间拿到的额度不同。
out-of-control 估算 vs 决策准确性
out-of-control 是仲裁器对风险空间的估算,不是一个可以精确计算的物理量。
- 收益:把未追踪内存、GC 滞后和 soft limit 都纳入统一安全边界。
- 代价:估算偏差会直接影响 SQL 成功率和实例稳定性。
风险
- 如果所有 SQL 都配置成高优先级,优先级调度会失效。
- 如果 soft limit 太低,SQL 会过早失败,资源利用不足。
- 如果 soft limit 太高,仍可能出现 GC 抖动或 OOM 风险。
- 如果 SQL 收到取消或强制终止后不能及时退出,内存释放会滞后。
- 如果未追踪内存长期偏高,逻辑额度的调度效果会下降。
结论
内存仲裁的本质,不是让系统更会强制终止 SQL,而是让执行引擎在资源紧张时有明确的决策顺序。
它把问题从:
1 | 谁用了最多内存? |
推进到:
1 | 系统还能不能继续分配? |
这就是执行引擎资源管控的核心。
正常情况下,内存仲裁应该尽量少打扰 SQL 执行;资源紧张时,它必须足够强硬,保护 TiDB 实例不被单个或一组 SQL 拖垮。
这套机制中最关键的难点,是在不精确知道所有内存归属的情况下,仍然做出足够保守但不过度保守的分配决策。out-of-control 的估算,就是这个难点的集中体现。
最终目标是形成一套统一的执行资源管控平面:业务策略决定资源优先级,执行引擎负责准入和调度,runtime feedback 负责校正真实状态,可观测性负责解释系统决策。