C++ 项目编译优化 —— TiFlash
面向
C艹(akaC++orCPP)的开发规范一直都比较松散,各个组织包括个体总能在不轻易间把项目堆成 xxxx xxxxxxxx。
随着工程规模增大,TiFlash 项目也逐渐开始暴露出这类问题:
- 头文件凌乱
- 模板滥用
- 编译缓慢
- 工程质量愈发难以控制
本文旨在提供量化指标和参考方法用以优化 C++ 工程项目的编译流程。希望动员社区的力量,一起来优化 TiFlash 的工程质量。
基础概念
普遍定义上,完整的编译流程分为以下几个流程:预处理(Prepressing),编译(Compilation)& 汇编(Assembly),链接(Linking)。相比于 GCC,LLVM 则有明显的前端(Frontend)后端(Backend)之分:
- 前端包括:处理头文件(Source),类/模板类解析(ParseClass),模版类实例化(InstantiateClass),模版函数解析(ParseTemplate),模版函数实例化(InstantiateFunction),代码生成(CodeGen Function)等。
- 后端则主要是以 Pass 框架 为基础的流程,可在 llvm-project/namespaces 中查看细节的实现。
C++ 编译器以源文件为编译单元,基本流程可参考 Phases of translation。Linux 动态链接库相关整理#Linux-动态库 这篇文章介绍过相关的几个案例(主要偏后端和链接器),可供参考。
以下所有的内容均默认编译器为 clang。
编译流程分析
编译 TiFlash 时加上 cmake 项 -DENABLE_TIME_TRACES=ON,即增加 clang 编译参数 -ftime-trace,令编译每个目标文件时以 json 格式输出相关分析追踪数据。可通过 chrome://tracing 或网站 Speedscope App 查看火焰图。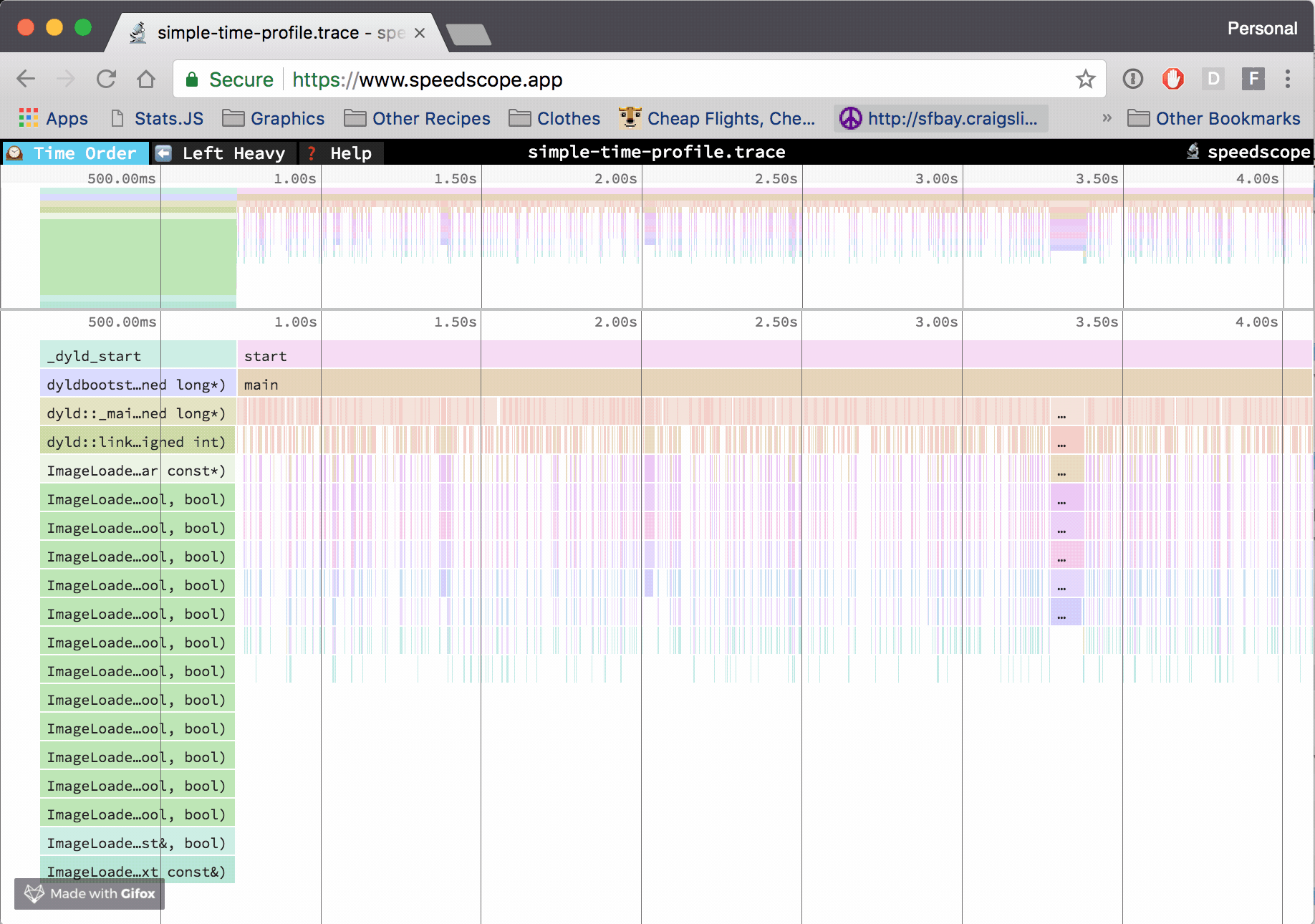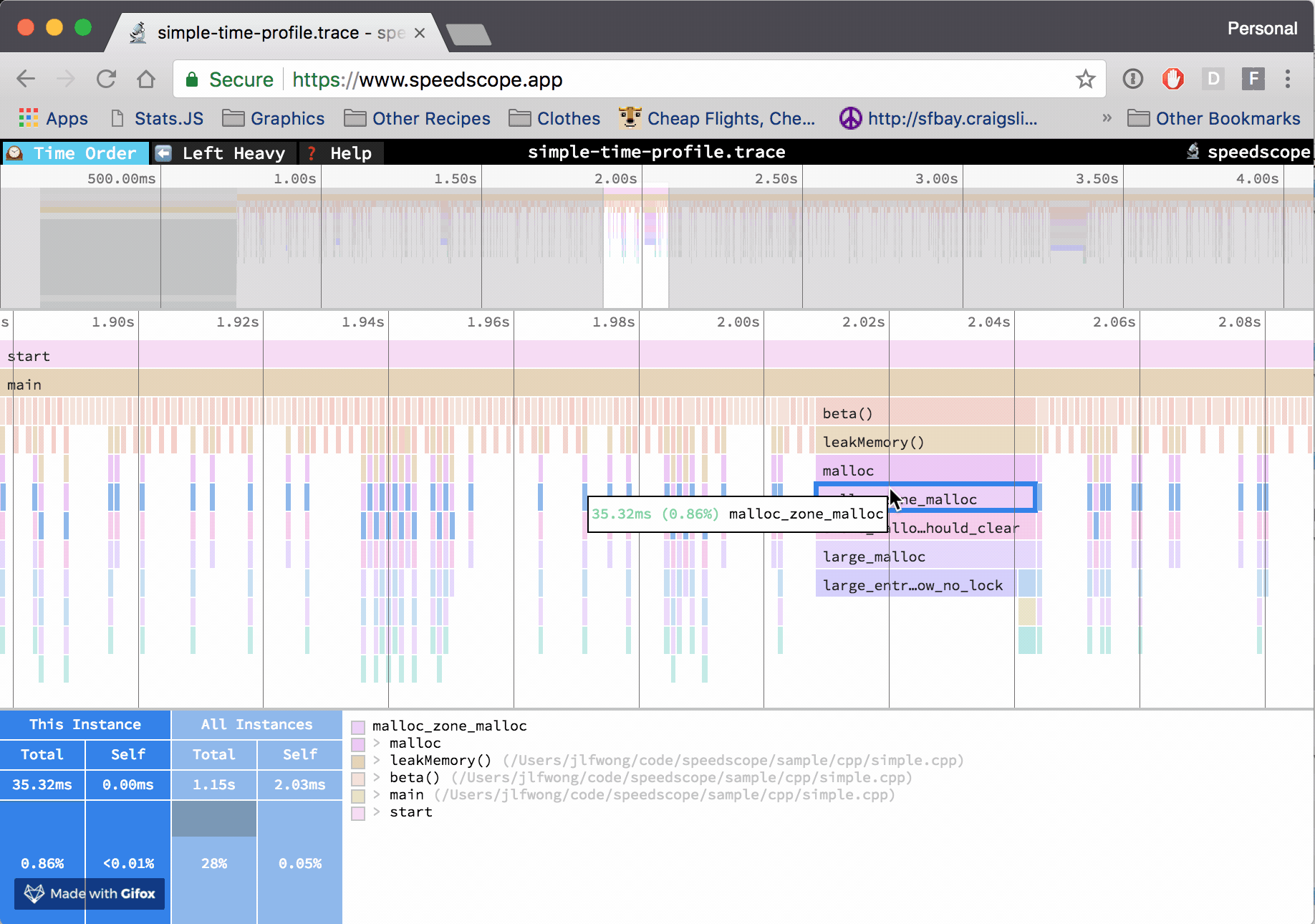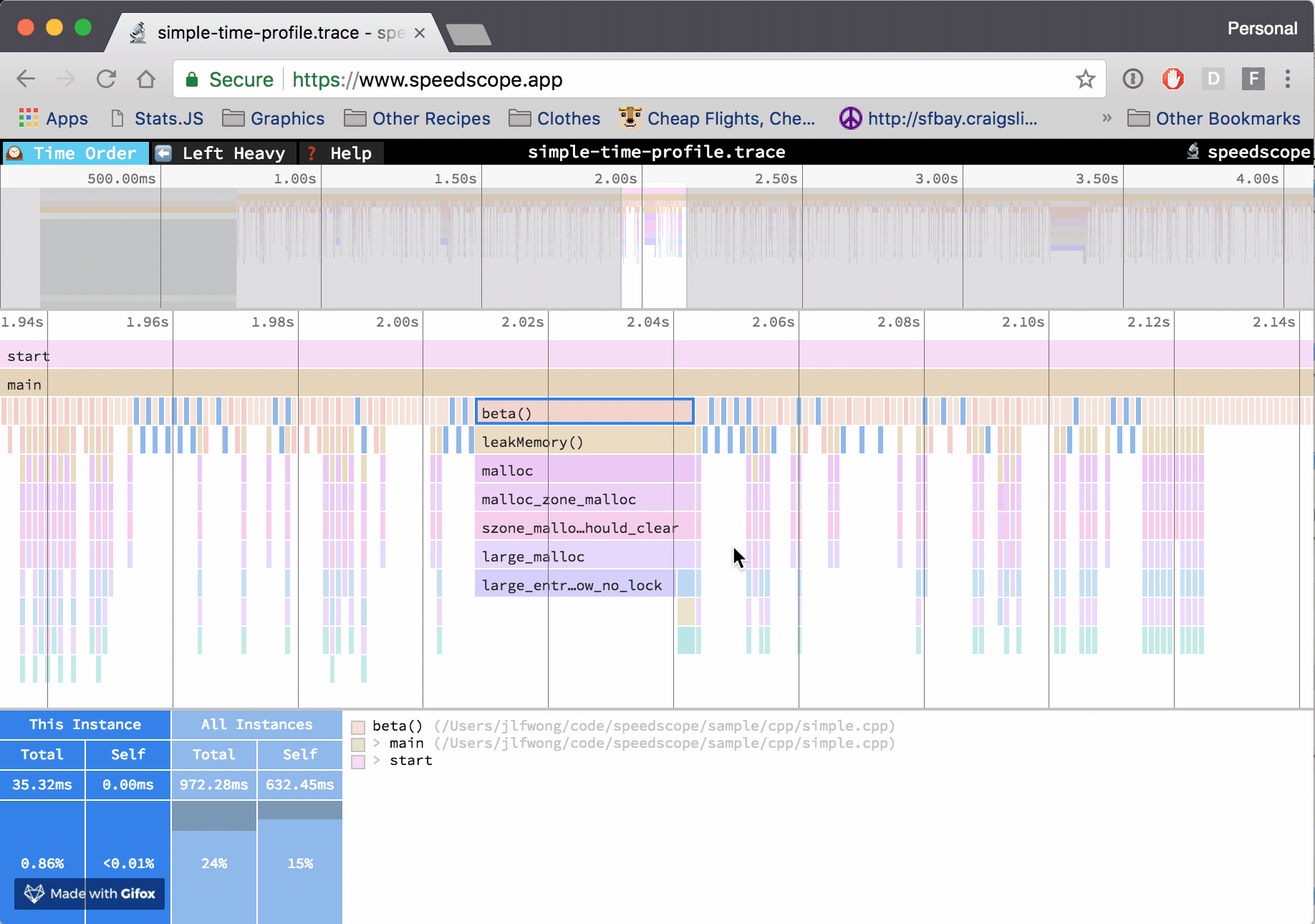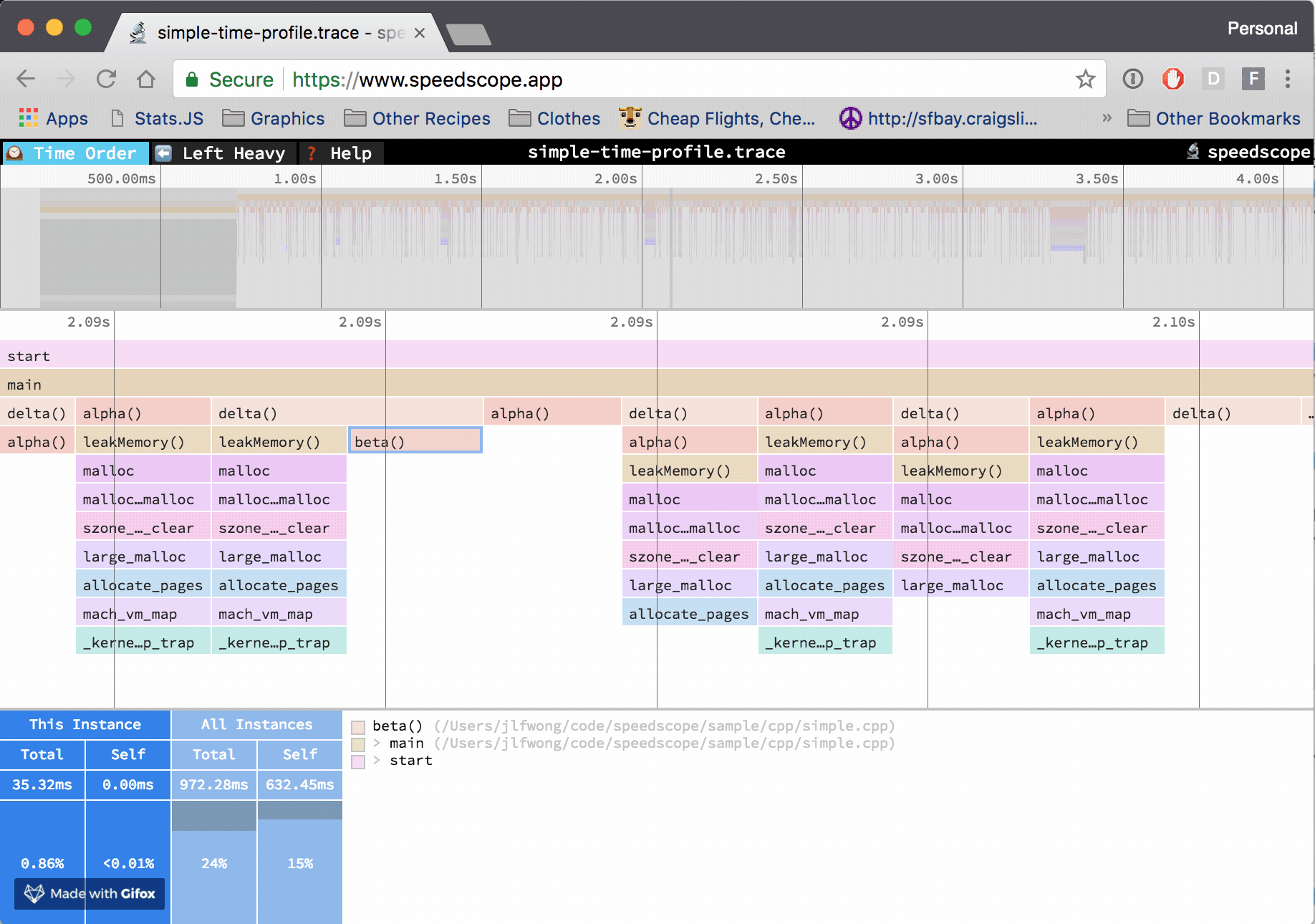
以这个 commit 的 TiFlash 代码为例 2d234262eb551b04b0ce304c7c6bacac847ca264。编译完成后,可以在编译路径 ${TIFLASH_BUILD_DIR} 下找到各个目标文件对应的 json 文件,例如 ${TIFLASH_BUILD_DIR}/dbms/src/Functions/CMakeFiles/clickhouse_functions.dir/FunctionsTiDBConversion.cpp.json。根据文章 Aras Pranckevičius - Clang Build Analyzer,通过工具 ClangBuildAnalyzer 分析 TiFlash 编译过程的各项属性:
1 | git clone https://github.com/aras-p/ClangBuildAnalyzer.git |
结果如下,前端居然比后端的总耗时还大,这非常 不合理。以下各个章节将针对此进行分析并简述优化过程。
ClangBuildAnalyzer 分析结果(未优化)
1 | **** Time summary: |
编译优化
目前使用的工具链是 LLVM-13,链接器 LLD 性能已经足够好,所以链接过程的速度暂时构不成瓶颈(理论上还有更快的 mold)。为获得更好的编译优化效果,较为推荐的是 LTO,不过代价就是更大的链接耗时和内存消耗。对于成熟的项目,利用 PGO 或 Post-link Optimizer 也可获得可观的收益。
就绝大部分实际场景而言(尤其是滥用模板的场景),少生成重复代码,便足以有效减轻后端的负担。
模板
对于大多数 C++ 工程项目而言,滥用 模板是万恶之源。
模板实例化
模板在什么时候会被实例化?
案例(1.0)
1 | // test1.h |
1 | clang++ -c test1.cpp -o test1.o -ftime-trace -std=gnu++17 |
用浏览器打开 test1.json 查看火焰图可知 std::unordered_map<int, int> 已经被实例化,且属于前端行为 ParseClass。意味着编译包含 test1.h 的源文件时均会产生这一重复行为。
1 | InstantiateClass {"detail":"std::__1::unordered_map<int, int, std::__1::hash<int>, std::__1::equal_to<int>, std::__1::allocator<std::__1::pair<const int, int> > >"} |
对于 test4 和 test5 也是同样效果。
1 | // test4.cpp |
1 | // test5.cpp |
1 | // test6.cpp |
然而,对于下面的 test2,火焰图中却看不到 std::unordered_map<int, int> 被实例化的过程。
1 | // test2.cpp |
分析(1.0)
对于编译过程来说 函数 和 变量 本身就是符号,编译器前端推导基于一定的规则。对于上述案例:
- test2 中虽然声明了
std::unordered_map<int, int>类型,但没有被实际的结构体定义或者函数实现依赖,编译器也就不需要实例化模板。 - 对于 test1/test4/test5/test6,编译器解析类或模板时识别出类模板
std::unordered_map在结构体或函数实现中被完整定义为std::unordered_map<int, int>类型,然后实例化该模板类。- test1:普通类成员函数
- test4:模板函数返回值
- test5:模板函数实现过程
- test6:模板类成员函数
需要重点关注的是:模板虽然在使用时可以看作是高级的宏命令,但如 test4/test5/test6 结果所示,即便编译单元最终生成的目标文件是空的(没有实际代码用到模板),编译器还是会推导并实例化模板。这个行为不符合常理,估计得看 C++20 的 Modules 能否完善。目前而言,只能靠优化模板定义和头文件依赖,或者参考 PImpl,PCH 技术。
案例(1.0.1)
类似于 test1.cpp 的场景理论上比较容易用 PImpl 改造。倘若是性能攸关的代码,无法忍受 PImpl 带来的局部性损失,可参考下面的方式,代价就是牺牲代码可读性以及使用模板的便利性。
std::unordered_map<int, int>akaData- 令
Test7::Inner的内存大小和对齐方式适配不同编译平台- 内存对齐方式(8 Bytes)与
Data相同(暂不考虑非 64 位平台或其他小众平台)。 Data在 MacOS 下是 40 Bytes,而 Linux 下则是 56 Bytes,本例子中直接取最大值(或可通过宏定义判断编译平台再设置大小)。
- 内存对齐方式(8 Bytes)与
- 在源文件中加上
static_assert以防止其他改动破坏基本假设。 Test7内部封装构造/析构、以及转换相关接口。- 当头文件 test7.h 被其他不相干的源文件所包含,编译器前端解析
struct Test7时则不需要再实例化std::unordered_map<int, int>。
1 | // test7.h |
1 | // test7.cpp |
案例(1.0.2)
类似 test4、test5、test6 的场景,可以将 std::unordered_map<int, int> 从模板实现之处消去,由调用方通过模板参数传入类型。
1 | // test8.h |
案例(1.1)
1 | // test9.cpp |
test9 中可以看到编译器前端在 PerformPendingInstantiations 阶段,实例化了模板函数 Test9_1::goo<int>,Test9_1::goo<bool>。因为编译器解析普通类成员函数 Test9_1::foo 的实现,至少要推导出这 2 个依赖函数的完整上下文,否则就会失败报错。
模板函数 Test9_1::koo 中调用了其他模板函数 Test9_1::goo<int64_t> 和 Test9_2<char>::foo。但这种仅仅在函数模板内调用其他模板函数的行为,编译器则默认不会实例化模板函数。同理,对于类模板 Test9_2,当显式声明实例化(template struct Test9_2<>;)后才能看到被实例化的模板函数 Test9_2<>::goo<float> 和 Test9_2<>::goo<double>。
案例(1.2)
test10 中的 struct Test10 同时定义了 3 个成员函数,并 显式 地实现了 Test10::goo,最终只有 Test10::goo 生成了对应的符号和汇编。
1 | // test10.cpp |
1 | ➜ clang++ -c test10.cpp -o test10.o -ftime-trace -std=gnu++17 |
当编译单元存在其他函数实现依赖 Test10::foo 和 Test10::foo2<> 时,才会生成相关的符号和汇编。对于这种 非显式 定义的函数,符号类型被设为 W / w(弱态),待链接时去重(即便不同源文件使用了相同头文件(例如各种 STL),最后也不会产生冲突)。
1 | // test10.cpp |
1 | ➜ clang++ -c test10.cpp -o test10.o -ftime-trace -std=gnu++17 |
删减重复模板实例化
案例(2.0)
根据 ClangBuildAnalyzer 分析结果,排名靠前的 FunctionsTiDBConversion.cpp,DAGExpressionAnalyzer.cpp,DAGExpressionAnalyzerHelper.cpp 都是重度模板使用者。而且 template <bool return_nullable> WrapperType createWrapper 是实例化耗时最久的模板函数。
1 | InstantiateFunction {"detail":"DB::FunctionTiDBCast::createWrapper<true>"} |
函数的模板参数是一个 bool 类型,全部枚举一遍也就是 2 种情况,共被实例化了 6 次显得很不合理。WHY ?
- 该模板函数作为普通类
class FunctionTiDBCast的成员函数,且直接在头文件 FunctionsTiDBConversion.h 中被另一个成员函数 WrapperType createWrapper(const DataTypePtr &, const DataTypePtr &, bool) const 调用。 - 包含 FunctionsTiDBConversion.h 的源文件(FunctionsTiDBConversion.cpp,DAGExpressionAnalyzer.cpp,DAGExpressionAnalyzerHelper.cpp)均会解析并实例化被用到的模板函数
DB::FunctionTiDBCast::createWrapper<false>、DB::FunctionTiDBCast::createWrapper<true>。按照调用逻辑,编译器会逐步实例化上百个相关的模板函数,例如DB::FunctionTiDBCast::createWrapperForDecimal<$> - DAGExpressionAnalyzer.cpp 和 DAGExpressionAnalyzerHelper.cpp 对 FunctionTiDBCast 没有逻辑依赖,所以目标文件中不会生成相关符号和汇编。
- FunctionsTiDBConversion.cpp 中则从 void registerFunctionsTiDBConversion(FunctionFactory &) 开始向上依赖 class FunctionBuilderTiDBCast -> buildImpl -> class FunctionTiDBCast -> 虚函数 ExecutableFunctionPtr prepare(const Block &) const -> WrapperType prepare(const DataTypePtr &, const DataTypePtr &) const -> WrapperType createWrapper(const DataTypePtr &, const DataTypePtr &, bool) const -> …
分析(2)
class FunctionTiDBCast 本身也就只在 DB::FunctionBuilderTiDBCast::buildImpl 函数中被创建使用。为了删除多余的模板实例化,一种简单的改动就如 tiflash/pull/4978
- 将 class FunctionTiDBCast 变成一个模板类
template <typename...> class FunctionTiDBCast - 把 DB::FunctionBuilderTiDBCast::buildImpl 的实现挪到源文件 FunctionsTiDBConversion.cpp 中。如此一来,即便其他源文件包含 FunctionsTiDBConversion.h,因为没有实际使用关系也就不会实例化该模板类及其成员函数。
改动效果如下,DAGExpressionAnalyzerHelper.cpp 的前端耗时从 185258 ms 下降到 20012 ms(降幅 89.2%),DAGExpressionAnalyzer.cpp 则是 181468 ms 降到 19898 ms(降幅 89.0%)。模板函数被实例化的次数也符合预期。
1 | **** Files that took longest to parse (compiler frontend): |
PS:理论上把头文件里非模板的实现都挪到源文件中(例如 案例(3.1)),可以达到相同的效果,现在这种方式无非是代码改动比较小而已。
拆分|合并编译单元
删减重复模板实例化之后,可以发现 divide.cpp 是最大的编译单元,编译器前端耗时 30783 ms,后端 416467 ms。后端耗时主要是编译这 4 个模板类 dbms/src/Functions/divide.cpp#L308-L333 以及其衍生出的template <typename... Ts, typename F> static bool castTypeToEither。巨大的编译单元令每次修改代码均陷入漫长的等待。为了充分利用多核资源,避免单核瓶颈,一种简单的方法就是把这 4 个函数及其相关的模板实例拆分到 4 个源文件中。
- 事实上之前 TiFlash 代码中注册这类 Function 函数的风格也是继承 Clickhouse,按功能独立拆分成:registerFunctionDivideFloating.cpp、registerFunctionDivideIntegral.cpp、registerFunctionDivideIntegralOrZero.cpp、registerFunctionTiDBDivideFloating.cpp 这 4 个源文件。
- 是在 92e668158c87893535d812773e4bfa501f0a2dc8 中这些源文件被合并成现在这样巨大的编译单元。
合并源文件所带来的好处包括以下几点:
- 减少头文件前端处理开销:例如某个头文件被多个源文件包含,每个编译单元都需独立解析一遍。
- 实际工程项目中也可通过 预编译头文件 来优化
- 减少重复编译:与 案例(1.2) 类似,头文件中有函数实现,每个编译单元用到该函数时均会生成相关的符号和汇编。但最终链接器只会为符号绑定一种实现。
- 利于编译器优化:普通编译优化无法跨编译单元
更有甚者,Unity build 通过把所有源文件合并成一个来避免上述开销。cmake 参数 CMAKE_UNITY_BUILD 也提供了这一支持。由于代码集中在单个编译单元内,有利于编译器全量分析上下文实现优化(比起 LTO 更加彻底)。但代价就是:
- 无法并行编译和增量编译
- 需解决静态变量或本地定义重名冲突
- 编译单元资源内存消耗峰值较大
就工程实践而言,为了兼顾开发效率,对于编译单元可以适度地拆分/合并。可参考的标准为:
- 根据 ClangBuildAnalyzer 分析结果中后端编译耗时的前几项,找出明显偏高的单元。
- 对于前端编译耗时相比于后端较低(例如小于 15%)的编译单元,则可根据逻辑模块进行拆分
- 对于前端耗时相比于后端较高的模块,则可以按需合并
- 理想情况下,期望所有编译单元的耗时接近平均值
显式实例化
基本概念参考 Explicit instantiation,核心语法为:
1 | template class-key template-name < argument-list > ; |
案例(3.0)
对于类/模板类的成员函数,即便声明了 extern template void Test11<>::foo_1<int64_t>(); 和 extern template void Test11<>::doo_1<int64_t>();,但火焰图仍显示了函数 Test11<>::foo_1<long long>,Test11<>::doo_1<long long> 被实例化的过程,和预期不符。只有函数模板声明了 extern template void foo_2<float>(); 后,火焰图中才没有任何相关的实例化过程。
1 | // test11.cpp |
1 | ➜ clang++ -c test11.cpp -o test11.o -ftime-trace -std=gnu++17 |
类可采用定义实现分离的方式来达到类似的效果,不过需要注意的是:如果模板函数有被实际用到(例如 test12_2.cpp),需要像 (1) 处在模板函数实现的源文件内显式实例化,否则会出现找不到相关符号的链接错误。
1 | // test12_1.h |
抽象出 ABI 稳定接口
如果类模板中实现了普通函数,则可将涉及到非模板的实现封装成独立的接口,以免每次模板实例化时生成重复代码。
案例(3.1)
每次实例化类模板,编译器均会生成函数 Node<xxx>::foo。如果采用定义实现分离的方式,则需要像 案例(3.0) 显式实例化每个被用到的模板类。
1 | // test15.h |
将函数分离到抽象类中,并通过类继承的方式封装,则最后只存在函数 NodeBase::foo。
1 | // test15_base.h |
头文件优化
头文件依赖
现有工具:
- 头文件分析工具 include-what-you-use 相对细致,但结果需要人工排查确认,成本较高。例如 TiFlash 的 cmake 编译选项 USE_INCLUDE_WHAT_YOU_USE。
- ClangBuildAnalyzer 工具输出项
Expensive headers比较简单清晰,展示头文件被包含的路径。需要人工分析依赖关系,找出瓶颈并优化(模板相关可参考上文)。
头文件依赖解耦,可列出说明使用文档和标准,让社区参与。
前向声明
前向声明(Forward declaration)是尚未给出完整定义的标识符(例如类型、变量、常量、函数)声明。编译器需要知道标识符的部分属性(内存大小和对齐方式,数据类型),但不用知道其他实现细节。
前向声明对于解耦头文件依赖有较大帮助。然而 Google C++ Style Guide 中却提出 Avoid using forward declarations where possible。比较关键的原因是在某些场景下,前向声明会导致代码静默行为产生变化,例如 案例(4.1)。
案例(4.0)
test13_2.cpp 中声明了前向定义 struct Test13_1;,并在 struct Test13_2 的成员函数和成员变量中引用。该源文件可以正常编译。
1 | // test13_2.cpp |
分析(4)
- 成员变量
Test13_2::data的类型实际是引用,其内存大小和对齐方式和指针相同,编译器解析时并不需要知道Test13_1的具体实现。 - 成员函数
Test13_2::foo引用了Test13_1,但编译单元内没有实现该函数,编译器则将其作为一个函数声明(本身也是种前向声明)。
案例(4.1)
class B 继承了 class A,如果隐藏类定义,则编译单元 test14.cpp 中 void test_14(B *) 最后会调用 f(void *),如果包含具体定义,在 test14_1.cpp 中则调用 f(A *)。
1 | // test14.cpp |
1 | // test14_1.cpp |
这个案例中引起不确定性行为的是 C++ 特有的函数重载和类继承方式:
void *指针可以匹配任意其他指针。test14_1.cpp中编译器优先按照继承关系匹配,由于不存在f(B *),则查找顺序为从f(A *)到f(void *)。test14.cpp中不存在继承关系,且不存在f(B *),则直接匹配到f(void *)。
解决这个案例中的问题,可参考以下途径:
- 去掉
f(void *)函数,令编译时直接报错,由开发者排查并补上继承关系。- 绝大部份实际应用中,比较常见的是子类继承并重写基类的虚函数,用
void *兜底很难说有什么实际意义。
- 绝大部份实际应用中,比较常见的是子类继承并重写基类的虚函数,用
- 在
f(void *)的逻辑实现中直接抛异常或手动 panic。
在代码设计和审查环节应当注意避开这类问题而非一味禁止使用前向声明。
预编译头文件(PCH)
Precompiled header(aka PCH):预编译(C 或 C++)头文件,使之被编译成编译器可以更快处理的中间形式,使用预编译头文件可以显着减少编译时间(主要是前端)。cmake 中支持 PCH 的语法为 target_precompile_headers。
- 在 Windows 系统下用 Visual Studio 开发桌面软件时经常能看到头文件
stdafx.h,里面基本会包含开发所用的重型 API。 - 参考 模板实例化 章节中的几个案例,编译器解析头文件会有不小的开销(尤其涉及到模板实例化),对于 TiFlash 这种 C++ 项目也是个不可忽略的问题。
案例(4.2)
根据 ClangBuildAnalyzer 分析结果,Expensive headers 中包含不少公共模块和 STL 库的头文件。5847f1c235b996eb6fb970029da926909e1819fd 为相关库编译选项加上 PCH:
pch-common.h包含 Exception.h,FmtUtils.h,StackTrace.h 之类的公共模块头文件pch-stl.h包含常用的 STL 库头文件,例如 algorithm,string,vector,functional 等pch-kvpb.h包含比较重型的 grpc 相关头文件
优化后,分析结果显示前端总耗时和重型头文件解析耗时显著下降。
1 | **** Time summary: |
PImpl
PImpl(Pointer to implementation)又称编译防火墙(Compilation firewall)。在类定义中隐藏数据结构的实现细节,只对外暴露不透明的指针/引用/其他固定类型作为访问入口。
- 例如发布二进制库给第三方,除了代码混淆,通常也需要用 PImpl 提供稳定的 ABI 并保护私有数据结构安全。
- PImpl 的劣势包括以下几点,如有必要可参考 案例(1.0.1) 来优化
- 需要分配额外的内存空间
- 存取变量时需要额外的内存寻址,对于看重 CPU Cache 和代码局部性的场景不利
案例(5.0)
根据 ClangBuildAnalyzer 结果,有关 struct TiFlashError 的几个模板实例化总开销不小。
1 | **** Templates that took longest to instantiate: |
使用这些模板的地方主要在 class TiFlashErrorRegistry。这种把成员函数实现直接放在头文件里的做法 不值得提倡,因为包含其的源文件均会解析并实例化涉及到的模板,建议分离定义和实现。
但是对于使用了 STL 模板的成员变量 std::map<std::pair<std::string, std::string>, TiFlashError> all_errors 则需要多加考量。
- 头文件中分离函数实现后,只要编译单元内没有其他符号对函数有依赖关系,编译器就可以不实例化函数涉及到的模板
- 对于类定义,编译器会解析其成员变量和依赖以确定大小和对齐方式。
分析上下文信息可知这个类主要以 单例 的形式用来维护/查找预设数据,可以使用 PImpl 改造以降低前端开销(对于该类的使用场景几乎不会有性能影响)。本案例中类重构效果如
TiFlashException.h#L192-L225。改造完成后,上面提到的模板实例化开销均被消除。
除了裸指针,用 std::unique_ptr 也是同样原理,例如 KVStore.h 的改动。
LTO(Link Time Optimization)
链接时优化(Link Time Optimization)是比较典型的后端优化,属于 Interprocedural optimization。LLVM 提供了强大的链接时跨模块优化功能,以获取更好的运行时性能。
ThinLTO 是一种新型的 LTO 技术。默认 full 模式的 LTO 会将所有目标文件整合成一个大模块,比较耗费资源且不可并行化扩展,同时这种方式也无法进行快速增量编译。ThinLTO 模式下,编译器生成的 bitcode 格式文件会额外包含模块的摘要(compact summary),链接器将这些摘要合并为索引,便于后期跨模块导入。链接器进行全局分析和优化也是基于该索引。
tiflash/pull/4890 中加入了 cmake 选项 ENABLE_THINLTO 并在 release build 流程中启用。跨模块优化的好处有以下几点:
- 全局优化:去虚拟化(
whole-program devirtualization),跨模块函数内联 - 删减无用代码
出于性能考虑,有人会放弃 前向声明 将函数直接实现在头文件中,这样有利于跨模块函数调用时编译器自动内联。有了 LTO 的支持,就无需担心这个问题(例如 案例(6.0)),将实现和定义分离有利于优化工程架构。
案例(6.0)
1 | // t1.cpp |
1 | // t2.cpp |
1 | // t3.cpp |
未启用 LTO,编译器优化无法跨模块。foo,sum,koo 函数的汇编实现无任何优化。
1 | clang++ -O3 -DNDEBUG -std=gnu++17 -o t1.o -c t1.cpp |
启用 LTO 后
foo函数逻辑直接被优化成等效于if (x > 0) return x * 100; else return x / 100;的实现sum中自动向量化生成 SIMD 指令koo去虚拟化实现等效于x + 6的逻辑
1 | clang++ -flto=thin -fvisibility=hidden -fvisibility-inlines-hidden -fwhole-program-vtables -fsplit-lto-unit -O3 -DNDEBUG -std=gnu++17 -o t1.o -c t1.cpp |
PGO(Profile-Guided Optimization)
PGO(Profile-Guided Optimization)也称 FDO(Feedback Directed Optimization),指通过工具采集程序运行时的 profile 数据,用以在重新编译流程中优化程序。
- FDO 的方案普遍被大厂用于优化数据中心的应用
- TiFlash 中支持 PGO:PR#5160
根据 llvm/docs/profile-guided-optimization,LLVM 的 PGO 主要分为 2 种:
- 代码插桩(Profiling with Instrumentation)
- 增加编译参数
-fprofile-instr-generate - 运行特定的 benchmark 负载,令程序自动采集 profile 数据(缺点是程序运行较慢)
- 重新编译时指定 profile 数据
-fprofile-instr-use=<xxx.profdata>
- 增加编译参数
- 运行时采样(Using Sampling Profilers)
- 增加编译参数
-gline-tables-only -fdebug-info-for-profiling -funique-internal-linkage-names,增加链接参数-Wl,--no-rosegment - 正常部署运行程序,利用 Linux Perf profiler 采集实际负载下的 perf 数据
- 较为推荐在支持 LBR(Last Branch Record)的平台上使用 -b 参数令 Perf 记录调用链信息,从而提升 perf 数据的精度
- 利用 AutoFDO 将 perf 数据转换为 LLVM 格式的 profile 数据
- 重新编译时指定 profile 数据
-fprofile-sample-use=<profile.prof>
- 增加编译参数
1 | perf record -p <pid> -e cycles:up -j any,u -a -o <perf.data> -- sleep 180 |
1 | create_llvm_prof --profile <perf.data> --binary <binary> --out=<profile.prof> |
采用代码插桩的方式对程序性能有较大影响,且无法采集真实环境数据,所以在实践中较为推荐运行时采样,即程序发布后采集线上真实 profile 数据并依此迭代更新(类似 Java 的运行时优化)。
案例(7.0)
该案例中虚函数 Extend::foo 被调用的频率明显高于 Base::foo,正常的 O3 优化可以按照一定的步长展开循环,但无法在运行时预测分支。
1 | // fdo-test.cpp |
1 | clang ./fdo-test.cpp -O3 -lstdc++ -Wl,--no-rosegment -gline-tables-only -fdebug-info-for-profiling -funique-internal-linkage-names -o ori.out -flto=thin -fvisibility=hidden -fvisibility-inlines-hidden -fwhole-program-vtables -fsplit-lto-unit -DNDEBUG -fuse-ld=lld -Rpass >pass.ori 2>&1 |
FDO 优化效果:编译器根据虚函数调用频率执行 Promote indirect call 优化,实现去虚拟化。
- 2012d8: 对比虚函数地址和
<_ZN6Extend3fooERi>函数地址是否相同 - 2012de: 如果比较相同则直接跳转到
2012c0 - 2012c0: 内联实现
<_ZN6Extend3fooERi>
1 | ./ori.out |
1 | # pass.new |
案例(7.1)
详见 tiflash#5160
TiFlash 以 commit 5b61ae70550624d3bf0b5ca6bac89013ed5a6a4b 为例
- 测试工具为 go-tpc,并以 tpch 负载用于 perf 采样和优化验证
- 单节点 tpch 10G 数据
- 通过 cgroup 限制程序最多使用 5 核
1 | mkdir -p /sys/fs/cgroup/cpu/pgo_test |
测试结果显示,对于重计算的场景例如 Q1,FDO+LTO 比起 LTO 的性能提升为 8.98%,相对于未做任何优化的版本提升 13.46%。Q13、Q18 之类的查询也因为聚合/过滤等计算占比较大获得一定的收益。而其他查询受计算模式中资源调度、数据瓶颈等因素影响存在一定的波动,优化效果不如 Q1 那么明显。
| Time Cost(s) | original | LTO | FDO+LTO | FDO+LTO : LTO | FDO+LTO : original | |
|---|---|---|---|---|---|---|
| Q1 | 6.32 | 6.07 | 5.57 | 8.98% | 13.46% | |
| Q2 | 2.99 | 2.99 | 2.92 | 2.40% | 2.40% | |
| Q3 | 2.79 | 2.65 | 2.65 | 0.00% | 5.28% | |
| Q4 | 1.91 | 2.05 | 1.85 | 10.81% | 3.24% | |
| Q6 | 0.91 | 0.91 | 0.84 | 8.33% | 8.33% | |
| Q7 | 2.38 | 2.32 | 2.32 | 0.00% | 2.59% | |
| Q8 | 4.8 | 4.73 | 4.73 | 0.00% | 1.48% | |
| Q9 | 16.81 | 16.54 | 16.48 | 0.36% | 2.00% | |
| Q10 | 3.72 | 3.72 | 3.66 | 1.64% | 1.64% | |
| Q11 | 0.5 | 0.5 | 0.5 | 0.00% | 0.00% | |
| Q12 | 1.98 | 1.91 | 1.85 | 3.24% | 7.03% | |
| Q13 | 4.66 | 4.6 | 4.33 | 6.24% | 7.62% | |
| Q14 | 1.04 | 1.11 | 0.97 | 14.43% | 7.22% | |
| Q15 | 2.05 | 1.98 | 2.11 | -6.16% | -2.84% | |
| Q16 | 1.04 | 1.04 | 0.97 | 7.22% | 7.22% | |
| Q17 | 5.67 | 5.8 | 5.67 | 2.29% | 0.00% | |
| Q18 | 8.62 | 8.41 | 7.99 | 5.26% | 7.88% | |
| Q19 | 3.12 | 3.05 | 3.05 | 0.00% | 2.30% | |
| Q20 | 1.58 | 1.58 | 1.64 | -3.66% | -3.66% | |
| Q21 | 2.99 | 2.85 | 2.89 | -1.38% | 3.46% | |
| Q22 | 0.64 | 0.64 | 0.5 | 28.00% | 28.00% |
3 节点跑 TPCH-100,限制每个节点 CPU 使用上限 1000%,结果如下
| Time Cost(s) | LTO | FDO+LTO | FDO+LTO : LTO |
|---|---|---|---|
| Q1 | 12.08 | 11.04 | 9.42% |
| Q2 | 4.33 | 4.26 | 1.64% |
| Q3 | 8.22 | 8.09 | 1.61% |
| Q4 | 21.17 | 21.64 | -2.17% |
| Q5 | 19.36 | 19.83 | -2.37% |
| Q6 | 1.91 | 1.85 | 3.24% |
| Q7 | 9.83 | 9.97 | -1.40% |
| Q8 | 11.98 | 11.58 | 3.45% |
| Q9 | 65.26 | 64.32 | 1.46% |
| Q10 | 10.57 | 10.37 | 1.93% |
| Q11 | 2.05 | 2.05 | 0.00% |
| Q12 | 5.2 | 5.27 | -1.33% |
| Q13 | 12.72 | 12.11 | 5.04% |
| Q14 | 2.18 | 2.11 | 3.32% |
| Q15 | 4.13 | 4.06 | 1.72% |
| Q16 | 2.32 | 2.25 | 3.11% |
| Q17 | 18.29 | 18.22 | 0.38% |
| Q18 | 23.12 | 22.85 | 1.18% |
| Q19 | 5.87 | 5.74 | 2.26% |
| Q20 | 4.06 | 4.13 | -1.69% |
| Q21 | 39.02 | 39.29 | -0.69% |
| Q22 | 1.38 | 1.31 | 5.34% |
除了 Q1,其他查询或多或少涉及到资源调度和等待,测试过程中无法全程打满 CPU,提升效果不如 Q1 那么明显。
Post-link Optimizer
TBD
编译缓存
Ccache 作为一种编译器缓存用于加速重编译过程。tiflash/cmake/find_ccache.cmake 也默认开启这一优化项来加速 CI 流程。C++ 的特性决定了头文件耦合程度会大幅影响编译缓存命中率,所以问题的核心又回到了 头文件优化。
根据文档 CCACHE - Precompiled headers,ccache 配合 PCH 一起使用时,需要注意设置参数 sloppiness=pch_defines,time_macros。
在实践中,我们发现 ccache 默认处理 PCH 时会判断相关文件的修改时间,当 PCH 中包含编译期生成的代码时(例如 protobuf )会导致相关目标文件缓存失败,对此需要进行更细粒度的划分和针对性调整。
就目前而言,ccache 主要用于日常开发以及 Pull Request 的 CI 流程(增量编译),PCH 则主要用于 release 编译(全量编译)。
社区|新开发者如何参与优化 TiFlash 项目
- 根据 tiflash/README.md 中的指示部署基本编译环境。
- 设置 cmake 项:
-DENABLE_TIME_TRACES=ON开启编译分析追踪-DUSE_CCACHE=OFF禁用 ccache-DENABLE_PCH=OFF禁用 PCH(目前先专注于优化头文件相关的开销)-DCMAKE_BUILD_TYPE=RELWITHDEBINFO或-DCMAKE_BUILD_TYPE=DEBUG需分别优化 2 种编译模式下的各项指标
1 | # prepare environment: llvm, rust |
- 编译后在 ${TIFLASH_BUILD} 中可获取每个目标文件的编译期火焰图
- 参考 编译流程分析 编译部署 ClangBuildAnalyzer,并用其分析 ${TIFLASH_BUILD}
- ClangBuildAnalyzer 的配置文件为 ClangBuildAnalyzer.ini,可根据官方文档调整参数
- 保存 ClangBuildAnalyzer 生成的中间文件和分析结果,作为对照组
- 根据 ClangBuildAnalyzer 分析结果,找出瓶颈点,参照上文进行优化
- CMAKE_EXPORT_COMPILE_COMMANDS 默认开启,可在文件
${TIFLASH_BUILD}/compile_commands.json中找到各个编译单元的执行命令。- 每次修改后,找到关联源文件的编译命令并手动执行,分析编译时的火焰图
- 可安装 include-what-you-use 后用 iwyu_tool.py 辅助。其中存在误报,需人工排查。
- 例如
iwyu_tool.py -p ${TIFLASH_BUILD} ${TIFLASH_WORKSPACE}/dbms/src/Storages/Transaction/TMTContext.cpp
- 例如
优化目标
- 编译前端耗时相对后端需尽可能小于 10%
- 令每个源文件编译耗时相对平均
- 降低总体编译耗时
- 优化 & 规范代码质量